Selma Lagerlöf och databasen
Vad händer om man släpper lös en nytänkande litteraturvetare på databasen över en stor författares samlade produktion? Litteraturvetenskapen har länge handlat om att läsa nära och noggrant, tänka och tolka. Men digitaliseringen har öppnat helt nya möjligheter att på statistisk väg analysera hur en författare skriver, vad de skriver om och hur allt detta förhåller sig till tiden de skrev i. Karl Berglund tar sig an Selma Lagerlöfs samlade verk på elektronisk väg och visar hur den digitala ”fjärrläsningen” ibland kan vända upp och ner på våra vedertagna uppfattningar om stora författare och deras litteratur.

Vi lever i en digital tid, brukar det heta. Digitaliseringen har påverkat i stort sett alla sektorer av samhället – också bokmarknaden och den litterära kulturen. För litteraturvetenskapen märks detta främst genom att stora mängder litteratur digitaliseras. I Sverige finns på Litteraturbanken delar av den äldre svenska litteraturen fritt tillgängligt. Ett nyss påbörjat forskningsprojekt vid Umeå universitet och Kungl. biblioteket ska digitalisera alla svenska romaner utgivna mellan 1945 och 1989. Och för bara några veckor sedan kom ett pressmeddelande där sex kungliga akademier och 30 internationella institutioner ställde sig bakom den långsiktiga plan för att digitalisera det skriftliga svenska kulturarvet som den nationella biblioteksstrategin har föreslagit. Samtidigt ger förlagen ut det mesta av den nya litteraturen (samt en hel del äldre titlar) som e-böcker. Allt större delar av den svenska litteraturen finns alltså tillgänglig för läsning i digital form, vilket i sig är enormt värdefullt för såväl allmänläsare som studenter och forskare. Förhoppningsvis kommer vi, precis som i Norge, förr snarare än senare att ha digital tillgång till mer eller mindre hela vår litteraturhistoria.
En annan effekt är att de digitala samlingarna möjliggör nya typer av litteraturanalyser. Med hjälp av datorstödda metoder kan man närma sig litteratur i digital form på andra sätt, i en annan skala. Litteraturprofessorn Franco Moretti var en av de första att uppmärksamma detta. År 2000 myntade han begreppet distant reading, fjärrläsning på svenska, som ett alternativ till litteraturvetenskapens etablerade tradition av nära läsningar. Moretti påpekade att de digitala textsamlingarna möjliggör storskaliga fågelperspektiv på litteraturhistorien, vilket i sin tur gör andra slags frågor möjliga att ställa. Kanske kan man säga att litteraturforskare har fått tillgång till en ny optik, som inte längre gör den egna beläsenheten till en absolut begränsning för undersökningens ramar.
Morettis fjärrläsningar uppstod förstås inte i ett vakuum. De bygger på en tradition av kvantitativ och empirisk litteraturhistorisk forskning, som länge existerat inom exempelvis litteratursociologi och bokhistoria, och som ligger metodiskt närmare samhällsvetenskaperna än humaniora. Vad Moretti föreslog var att kombinera sådana angreppssätt med potentialen i digitala textsamlingar. Därigenom kunde de kvantitativa perspektiven förflyttas till litteraturvetenskapens kärna: litteraturanalysen. Och så var fjärrläsningen född.
Termen fick snabbt ett stort genomslag, mycket tack vare sitt visionära anslag och sin polemiska retorik gentemot mer hävdvunna litteraturvetenskapliga metoder. Moretti talade om en ”mer rationell typ av litteraturhistorisk forskning”, efterföljare som Matthew Jockers om att närläsningen som metod är att betrakta som obsolet i digitaliseringens tidevarv. Polemiken rörde samtidigt upp starka känslor. Länge präglades debatten av en polarisering mellan kvantitativa och kvalitativa perspektiv, som om det vore en fråga om att välja sida. Under senare år har dock allt fler forskare lyft nyttan av att kombinera perspektiv, inte sällan genom att använda olika typer av datorstödda fjärrläsningar som en bakgrund för vidare kvalitativa analyser.
Humanister sätter stort värde i att värna det komplexa, det mångfacetterade och det som inte enkelt låter sig beskrivas eller kategoriseras. Men fjärrläsningar liksom alla andra kvantitativa metoder förutsätter entydiga kategorier och uppdelningar. Litteraturforskaren behöver därför kvantifiera sin data till enheter som går att räkna på. Detta kallas för operationalisering och är en grundförutsättning för dessa metoder.

Perspektivet innebär samtidigt att forskaren måste bortse från tvetydigheter och vagheter i materialet. Och här uppstår en konflikt med den humanistiska grundsynen. Fjärrläsningar tvingar forskaren att förenkla litteratur och litterär kontext till mätbara byggstenar. Naturligtvis går vissa nyanser förlorade i den här processen. I gengäld går det att med datorers hjälp hitta mönster i textmaterial som mänskliga läsare inte ser. Dessutom vinner man annat: storskalighet, exakthet, möjlighet att upprepa experiment eller genomföra dem igen med förändrade parametrar.
Forskare som applicerar kvantitativa och datorstödda analyser på litteratur måste också vara konkreta i sin beskrivning av hur man har gått tillväga, varför man har gjort de val man gjort och vilka effekter det har fått. Litteraturvetaren Sarah Allison menar att det här är nyttigt för litteraturforskningen, eftersom den i vanliga fall inte sällan tenderar att vara ganska diffus när det gäller hur analyser faktiskt är utförda. Dessutom, påpekar hon, är alla litteraturanalyser reduktiva i någon mening. Även en traditionellt argumenterande och kvalitativ litterär analys lyfter fram vissa aspekter av en text och bortser från andra. Men det är bara kvantitativa och datorstödda metoder som öppet redovisar hur de går till väga. Genom att vända på perspektivet synliggör Allison att de digitala metodernas begränsningar också kan ses som en analytisk styrka.
Vad kan man då åstadkomma med dessa metoder? En hel del olika saker förstås. I det följande tänkte jag använda Selma Lagerlöf som exempel – dels för att hon är en av våra allra största författare, som det forskats om massor genom åren; dels för att hennes författarskap finns digitaliserat i sin helhet, tillgängligt via Litteraturbanken. Exemplet Lagerlöf kan förhoppningsvis belysa hur digitala litteraturanalyser kan ge nya ingångar också till den litteratur det redan finns starka och vedertagna uppfattningar om.
Samtidigt ska det framhållas att analyser av detta slag ingalunda bör begränsas till den mer kanoniserade litteraturen. Tvärtom: en central poäng med fjärrläsningar är att de kan ta hänsyn också till all den litteratur som vanligtvis inte uppmärksammas inom litteraturvetenskapen – den perifera eller bortglömda litteraturen, populärlitteraturen, ja allt det som hade en plats i offentligheten när det gavs ut, men som sedan fallit i historiens glömska. Franco Moretti kallar detta för ”the great unread” – uppskattningsvis 99,5 procent av den utgivna litteraturen.
Med fjärrläsning går det att jämföra översättningar eller olika utgåvor med stor precision. Inte minst det senare skulle vara av stort intresse eftersom Lagerlöf ofta reviderade sina verk i senare utgåvor. Vad gäller mer klassisk litteraturanalys kan man schematiskt skilja på stilistiska, tematiska och berättartekniska möjligheter. Om vi börjar i det stilistiska så finns det en mängd utsagor och föreställningar om vad som är utmärkande för Selma Lagerlöfs prosa. Litteraturhandboken (1999) beskriver hennes stil som ”personlig, lyriskt sublim och talspråksmässigt enkel, impulsiv och fantasifull”. Den senaste upplagan av Litteraturens historia i Sverige (2013) talar om ”starka drag av poetisering” och Anna Nordlund nämner i Selma Lagerlöf. Sveriges modernaste kvinna (2018) författarens modernisering av svenska språket och drivkraften att vara lättläst. En datorstödd ansats till att studera Lagerlöfs stil och förändringar över tid måste, som sagt, närma sig frågan på ett mer konkret sätt.
Ett sätt är att undersöka vokabulär och ordförråd. Hur stort antal unika ord använder Lagerlöf? Skiljer det sig åt mellan hennes verk? En enkel jämförelse visar att hennes två första verk – Gösta Berlings saga och Osynliga länkar – har störst ordförråd, vilket snabbt ger upphov till en rad följdfrågor: Hur ser det ut om jämförelsen expanderas till att inkludera fler mått såsom genomsnittlig ordlängd, meningslängd och styckelängd? Eller om vi studerar vilka ord eller flerordskombinationer som är statistiskt sett överrepresenterade? Fäller något verk ut eller är Lagerlöfs oeuvre stabilt sett till dessa aspekter? Och hur ser det ut om Lagerlöfs prosa jämförs med andra författares, antingen med hennes samtida eller med andra kanoniserade svenska författarskap? Skiljer Selma Lagerlöf ut sig i språklig modernitet? Traditionell handbokskunskap säger att Strindberg är svenska språkets största förnyare, medan en forskare som Carin Östman har lyft fram också Lagerlöfs roll som språkförnyare. En datorstödd analys kan förmodligen understödja Östmans argumentation och visa varför Strindbergs prosa idag upplevs som mera svårläst än Lagerlöfs.
Resonemangen och följdfrågorna ovan illustrerar väl hur arbetsprocessen vid digitala litteraturanalyser ofta ser ut. Man börjar på ett ställe, genom att undersöka något förhållande. Och utfallet – som ofta är oväntat, eller åtminstone inte på förhand givet – ger i sin tur upphov till nya frågor, vilket leder till nya körningar och nya resultat. Man provar sig fram, ställer frågor till materialet och reviderar frågeställningar efter hand.
Med fjärrläsning går det att jämföra översättningar eller olika utgåvor med stor precision.
Något liknande görs förstås vid alla slags litteraturanalyser, men här finns en stor skillnad i arbetsinsats. För att vid kvalitativa analyser kunna pröva en ny metodisk ingång eller en jämförelse mot ett nytt material krävs i regel gott om ytterligare inläsningstid (eller möjligen: encyklopediska förkunskaper). För att vid datorstödda kvantitativa analyser kunna göra det motsvarande krävs att man laddar in nytt material i programvaran och gör nya körningar, eller att man reviderar sin kod till att utföra den uppdaterade kalkyleringen. Kort sagt är det väldigt mycket enklare att pröva alternativa synsätt eller komparationer vid fjärrläsningar, vilket i sin tur gör att såväl forskningsfrågor som resultat blir mer öppna och mindre tesdrivna. Istället för att närma sig en forskningsfråga utifrån en tydlig bild av vad man tror att man kommer att hitta erbjuder fjärrläsningen ett mer prövande förhållningssätt.
Samtidigt ska det betonas att enbart resultatgenererande inte säger särskilt mycket. För att komma åt intressanta forskningsfynd behöver man vara inläst på ett författarskap. Eller ha tillgång till extern domänexpertis. Fjärrläsningen inbjuder till samarbeten mellan forskare med olika kompetenser, som kompletterar varandra. Överlag är samarbeten något som genomsyrar hela fältet digital humaniora, vilket är en stor skillnad mot humanioras annars förhållandevis vedertagna solistkultur. Fjärrläsningar är ofta något som görs i grupp.
Stilistiska analyser kan även göras av mer avancerat slag. Med hjälp av ordklasstaggare kan man med stor säkerhet automatiskt avgöra vilken ordklass varje ord i en text tillhör, information som sedan kan användas vidare. Vilket av Lagerlöfs prosaverk har störst andel adjektiv? (Svaret är berättelsesamlingen En saga om en saga och andra sagor; den självbiografiska tonårsberättelsen Dagbok. Mårbacka III har lägst andel.) Finns det särskilt adjektivrika avsnitt i hennes böcker? Använde Lagerlöf fler eller färre adjektiv än sina generationskamrater? Vilka verb är de mest överrepresenterade i varje enskilt verk av Lagerlöf? Vilka är de mest överrepresenterade verben sett till hela hennes författarskap, om man jämför med andra kanoniserade författare? Svaren på dessa och liknande frågor kan fungera som kvantitativ grund för mer djuplodande, kvalitativa stilistiska analyser.
Ett ytterligare användningsområde är att det går att bryta ut särskilda stilfigurer eller delmängder. Vill du studera alla meningar som börjar med en viss typ av satsbyggnad, som innehåller två eller fler adjektiv eller som blandar tempus? Inga problem. En taggare kan automatiskt och med hög precision avgöra varje ords ordklass i en digital text. Om denna information paras med ett reguljärt uttryck (en notation som exakt matchar uppställda syntaxregler) går avgränsningar likt dem ovan att göras i princip hur detaljerade som helst. Och när väl delmängden har sovrats fram finns alla möjligheter att vidare jämföra delen med helheten, på önskad nivå av specificitet: inom litterära verk, mellan verk, mellan författare.

Eftersom Lagerlöf genomgående använder citationstecken för att anföra dialog kan man också separera dialog från övrig text i hennes prosa, vilket aktualiserar fler frågeställningar: Har Lagerlöf ett annorlunda språk i sin dialog än i sin berättande text? Ett modernare? Eller ett mer dialektalt? Finns det tematiska skillnader? Har dialogen olika funktioner i olika romaner? Hur används dialog för att berätta och hur används dialog för att sceniskt gestalta? Förändras hennes sätt att skriva dialog över tid? Och vad säger svaren på sådana frågor om Lagerlöfs stil och berättarteknik i ett större perspektiv?
Även om stilistik intresserar många är förmodligen semantiska ingångar än mer användbara för litteraturforskning. Det vill säga: analyser som berör tematiska aspekter på olika nivåer; vad verk ”handlar om”, kort och gott. Den enklaste ingången för tematisk fjärrläsning, som de flesta idag är bekanta med i olika sammanhang, är sökningar på ord, ordstammar eller ordföljder i ett material. I typfallet genereras en träfflista, där forskaren kan se alla förekomster av sökordet, vart och ett inom sin avgränsade kontext. Sådana konkordanslistor – eller key word in context (KWIC) som de också kallas – är basala redskap, men de ska fördenskull inte avfärdas. Tvärtom kan man komma ganska långt på enkla slagningar.
Är man exempelvis intresserad av blod som motiv eller metafor är det snabbt gjort att hitta alla förekomster av ordledet ”blod” i Selma Lagerlöfs utgivna fiktionsprosa (i alla dess former, det vill säga inklusive ”blodets”, ”blodtörst”, ”blodstörtning”, och så vidare; det finns 241 stycken). Därefter kan man antingen överskådligt granska orden i den litterära texten för vidare analyser, eller diskutera hur motivet är fördelat över Lagerlöfs verk. (Mest blod förekommer i Gösta Berlings saga, Osynliga länkar och Antikrists mirakler.) Potentialen för vidare breddning är stor då metoden snabbt kan generera tematiska överblicksbilder också över mycket omfattande textmaterial. Är blod främst kopplat till genre? Eller till författarskap? Är användningen tidsbunden? Och så vidare.
På liknande sätt kan man undersöka användningen av mer vanligt förekommande ord. Ett sätt att åstadkomma en grundläggande genusanalys av ett litterärt verk är att räkna könsbestämda pronomen, det vill säga ”han” och ”hon”. Naturligtvis är detta ett grovt och trubbigt mått, men nog säger det något om innehållet att förhållandet mellan antalet ”hon” och antalet ”han” i Gösta Berlings saga är 0,81 medan det i August Strindbergs Röda rummet är 0,10. Det vill säga: Medan det går fyra ”hon” på fem ”han” i Lagerlöfs debut är samma förhållande i Strindbergs genombrottsroman en på tio. Röda rummet är helt enkelt en klart mer ensidigt manligt könad historia. Detta förvånar förstås ingen som är bekant med de två romanerna, men styrkan i detta slags enkla mått ligger i att de är så lätta att skala upp. Gör vi samma jämförelser över några hundra klassiska svenska romaner, eller över ett större antal hela författarskap, framträder genast mer intressanta och säkerligen till viss del oväntade mönster. Återigen: fjärrläsningen erbjuder en ny optik, som förändrar hur vi kan betrakta litteraturhistorien.
En andra nivå av tematisk analys är att rikta blicken från sökord till kontexten eller diskursen kring dem. Ett ofta citerat påstående inom lingvistiken är den så kallade distributionshypotesen: ord får sin betydelse genom ”the company it keeps”. Ett sätt att fånga sådana ordsällskap är genom kollokationer, listor över de ord som oftast förekommer i närheten av ett sökord – antingen i absoluta tal eller i statistisk mening. Ett illustrerande exempel är den nyss nämnda sökningen på könsbestämda pronomen. I tabellen nedan har jag beräknat de statistiskt sett mest överrepresenterade orden i kontexten kring ”han” respektive ”hon”, här definierat som fem ord framför och fem ord efter varje träff samt med de mest sällsynta orden borttagna.
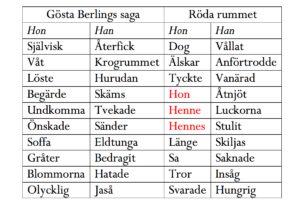
Tabell 1. Topp tio överrepresenterade ord som förekommer minst fem ggr i kontexten kring ”han” och ”hon” i Gösta Berlings saga respektive Röda rummet
Här finns många saker man skulle kunna gå vidare med. Mest noterbart vid en första anblick är förmodligen att orden ”hon”, ”henne” och ”hennes” samtliga återfinns bland de tio mest överrepresenterade orden i kontexten kring ”hon” i Strindbergs Röda rummet. Granskar vi några av dessa träffar närmare blir det tydligt varför:
[…] gå in i smårummen och skicka efter henne. Hon kan ju säga, att det har […]
[…] att skaffa någon förströelse. – Om jag kände henne?! Hon var vid teatern i X-köping […]
[…] Att se henne, den oskyldiga flickan, se henne hur hon lider och blyges, då hon […]
[…] flickan? Agnes? – Jo, jag tyckte mycket om henne! – Och hon är kär i dig! Det […]
[…] Du skall vara snäll och hålla med henne, om hon säger att hon tror barnet […]
Vad det handlar om är meningar där företrädesvis män talar om kvinnor. Inte nog med att kvinnor förekommer långt mycket mer sällan i Röda rummet än i Gösta Berlings saga. När de väl förekommer är det ofta som varandes omnämnda av män, snarare än som egna subjekt.
Inte heller detta är något litteraturhistoriskt scoop. Men styrkan med fjärrläsningen, i jämförelse med vanliga litteraturanalyser, ligger här åtminstone på två plan. För det första går litteraturhistoriska argument att statistiskt belägga (eller motbevisa, eller kanske oftast: nyansera). Och en kvalitativ analys som tar avstamp i ett kvantitativt belägg får mer tyngd. För det andra kan körningar snabbt justeras så att de täcker ett långt mycket större material. När det gäller storskalighet är digitala metoder, vågar jag nog påstå, överlägsna mer traditionella läsningar.
Såväl konkordanser som kollokationer bygger dock på av forskaren inmatade sökord. Utan sökord, ingen output, ingenting att tolka. För att få ut något av sådana metoder måste man ha en ganska tydlig föreställning om vilka ord som är viktiga och varför. Detta bygger på sökrutans logik, vilket inte alltid är önskvärt; det riskerar att premiera sökord vi redan känner väl till, där vi mer eller mindre vet vad vi vill hitta (som i mina exempel med ”hon” och ”han” nyss). Ibland behöver analysen börja i en annan ände.
Kritiker av fjärrläsningar brukar ofta triumferande poängtera att det enda dessa metoder kan göra är att räkna ord.
Dessutom är det långtifrån allt som går att bryta ned till väl fungerande sökord. Ibland skapar homonymer och homografer en massa oönskade träffar som försvårar eller omöjliggör kvantitativa analyser. Ibland är de tematiska koncepten vaga och mindre styrda av en tydlig vokabulär. Ibland är det vi letar efter av anakronistiskt art, det vill säga företeelser som idag är klart definierade men som vid den undersökta tiden inte var det på samma sätt.
I fall som dessa får vi vända oss till mer avancerade statistiska metoder. Inom humaniora är den hittills mest använda topic modeling. Kortfattat är det en matematisk modell som genererar kluster av sammanhörande ord utifrån grundantagandet att textdokument innehåller latenta teman, och att varje tema har större sannolikhet att innehålla vissa ord och lägre sannolikhet att innehålla andra. Exempelvis är det sannolikt att ett textavsnitt som handlar om ett kyrkobesök kan innehålla ord som kyrka, präst, psalm, predikstol, och så vidare. Att förstå intuitionen bakom hur topic modeling fungerar är relativt lätt. Att förstå den matematiska modellen är dock svårare, åtminstone för en humanist. Men topic modeling har använts förtjänstfullt i många olika sammanhang och det blir alltmer vedertaget att metoden producerar tillförlitliga resultat (även om kritik inte saknas).
Förenklat stoppas två saker in i modellen: ett stort antal textdokument, som utgör den korpus modellen körs på; samt en angivelse av det antal ”topics” man vill att modellen ska sortera korpusens ord i. Båda dessa ting är förstås helt centrala för de resultat som ges. Rätt använda erbjuder de också utmärkta möjligheter för att justera modellen utifrån vad man är intresserad av. Storleken på textdokumenten avgör hur den tematiska kontexten i den litterära texten avgränsas. I litteraturforskning är det vanligt att utgå från stycken eller delar av stycken. (Att utgå från hela romaner som textdokument skulle producera mindre intressanta resultat eftersom det implicerar att varje roman behandlar endast ett tema.) Antalet ”topics” avgör vilken nivå av tematisk specificitet man letar efter. Om modellen fördelar in alla ord i 20 ”topics” genereras breda ordkluster. Om modellen istället fördelar in alla ord i 200 ”topics” genereras många och smala ordkluster.
Och dessa kluster påminner i hög grad om vad en läsare intuitivt skulle kalla för teman. När vår forskargrupp lät modellen leta efter 20 ”topics” – dvs få, bredare teman – i en större samling svenska romaner från Litteraturbanken, där bland annat all Lagerlöfs fiktionsprosa med modern eller moderniserad stavning ingår, hittade vi teman med toppord som:
[7] älska, kärlek, hjärta, sorg, gråta, lida, hata, lycka, hat, tår, …
[8] peng, köpa, betala, sälja, arbete, skaffa, krona, arbeta, arbetare, kosta, …
[9] sol, blomma, träd, himmel, jord, stjärna, luft, snö, moln, skog, …
Att tyda vad dessa ord signalerar i termer av tematik är inte svårt. Ett förslag till tolkning skulle kunna vara: 7) starka känslor, kärlek och hat; 8) pengar och arbete; 9) väder, natur, utomhusmiljöer. Utfallet kan sedan användas för olika analyser. Man kan undersöka vilka verk i en stor litterär korpus som har en hög grad av ett särskilt tema och ha det som kvantitativ utgångspunkt för en kvalitativ tematisk analys. Man kan spåra teman genom litteraturhistorien och se var de först dyker upp, när de är som mest populära och när de avtar. Man kan se hur särskilda teman fördelar sig över ett författarskap. Exempelvis är topic 7 ovan (”starka känslor, kärlek och hat”) klart överrepresenterat i Lagerlöfs Gösta Berlings saga och Körkarlen, men lika klart underrepresenterat i Nils Holgerssons underbara resa och i den självbiografiska Mårbackasviten, vilket ter sig som ett rimligt utfall med tanke på verkens karaktär.
Men hur ser det ut vid andra, mindre självklara jämförelser? Litteraturens historia i Sverige hävdar exempelvis ”det ständigt återkommande temat i Selma Lagerlöfs berättelser, det som gäller skuld, straff och försoning”. Är det något som går att kvantitativt belägga (eller problematisera) om Lagerlöf jämförs med andra författare? Närmast ovan i vår undersökning (vid 100 topics) var topic 94, som innehåller både ”straff” och ”försoning” bland topporden, men också ord som ”synd”, ”nåd”, ”helvete”, ”gärning” och ”religion”, det vill säga ett starkt religiöst förankrat tema kring straff och skuld. Och här är Lagerlöf inte överrepresenterad alls, snarare tvärtom. Flera av hennes verk, som till exempel Nils Holgersson och Ett barns memoarer, har bland de absolut lägsta andelarna av temat i hela urvalet. Det tyder på att skuld, straff och försoning inte är så särpräglat för Lagerlöf som litteraturhistorieskrivningen gör gällande, eller åtminstone att det är en bild som kan diskuteras.
Det fina med topic modeling ur litteraturhistorisk synvinkel är att det möjliggör storskaliga tematiska analyser helt utan semantisk input från forskaren. Därmed kan modellerna användas som en sorts statistiska korrektiv, som prövar hypoteser utan den styrning som sökord ger upphov till. Intresserar du dig exempelvis för telefonsamtal i litteraturen är det lätt att se telefonsamtal överallt och därigenom överdriva deras litterära betydelse. Topic modeling kan ge en snabb översiktsbild och spåra omfattningen och framväxten av ett sådant tema.
Dessutom är naturligtvis de enskilda orden i temana av stort intresse. I vår studie jämförde vi svenska litterära klassiker med 2000-talets bästsäljare och fann bland annat att teman som ”mat” och ”pengar” var närvarande i båda dessa korpusar. Eftersom detta rör allmängiltiga företeelser är utfallet inte förvånande i sig, men det gjorde det möjligt att betrakta hur dessa teman semantiskt hade förändrats. Kaffet och vinet bestod men brännvinet försvann, till exempel. Och temat kring pengar och ekonomi var starkt knutet till det egna arbetet kring sekelskiftet 1900, medan det hundra år senare främst handlade om företag, banker, storfinanser och kunder.

Berättartekniska fjärrläsningar är ett område där forskningen ännu är förhållandevis liten, men där det finns stora möjligheter för nytänkande framgent. Utgångspunkten är distribution (av ord, ordklasser, stilfigurer, teman eller något annat) inom verk, vilket i regel visualiseras med grafer där x-axeln visar romantid och y-axeln förekomst. Vad som lyfts fram beror förstås på frågeställningen. Hur särskilda stilfigurer distribueras kan utgöra utgångspunkten för en retorisk analys. Hur teman fördelas kan berätta viktiga saker både om innehåll och komposition.
Litteraturvetarna Jodie Archer och Matthew Jockers har använt en så kallad sentimentanalys – en analys av positivt och negativt laddade ord – för att spåra återkommande dramatiska kurvor i stora litterära textsamlingar. Jag själv har för samtida svensk kriminallitteratur räknat när mördarens namn nämns i förhållande till när hen avslöjas och på så sätt kunnat teckna en grundläggande typologi över hur mordgåtor konstrueras. Jag fann sex typer som var återkommande och spridda i hela mitt urval. Med andra ord byter deckarförfattare ofta typ av mordgåta mellan romanerna i sina serier, vilket när man tänker närmare på det inte är så konstigt. Intentionen är förstås att samtidigt överraska läsaren (genom mordgåtan) och låta det välbekanta träda fram (genom romangestalter, miljöer och stil).
Kritiker av fjärrläsningar brukar ofta triumferande poängtera att det enda dessa metoder kan göra är att räkna ord. Och även om det går att räkna betydligt fler saker än ord så stämmer det: fjärrläsningar handlar om att räkna. Det är i grunden dumma metoder, och inte litterära analyser i egen rätt. Men i och med att beräkningarna går att göra så snabbt kan de förenkla eller stödja en litterära analys och visa på mönster vi inte hade haft möjlighet att se annars. Med andra ord är nog det verkligt dumma att inte dra nytta av maskinernas beräkningskraft – bara för att det handlar om litteratur.
KARL BERGLUND är fil. dr i litteraturvetenskap vid Uppsala universitet. Han disputerade 2017 på avhandlingen Mordens marknad: Litteratursociologiska studier i det tidiga 2000-talets svenska kriminallitteratur. Han är också verksam som kritiker och som bibliotekarie med inriktning på digitala metoder vid Uppsala universitetsbibliotek.
bibliografi
Sarah Allison, Reductive Reading: A Syntax of Victorian Moralizing, Baltimore: Johns Hopkins University Press, 2018
Jodie Archer & Matthew Jockers, The Bestseller Code: Anatomy of the Blockbuster Novel, New York: St. Martin’s Press, 2016
Karl Berglund, “Killer Plotting. Typologisk intriganalys utifrån fjärrläsningar av 113 samtida svenska kriminalromaner,” Tidskrift för litteraturvetenskap, (3–4), s. 41–68
Nan Z. Da, ”The Computational Case against Computational Literary Studies”, Critical Inquiry, 2019:1, s. 601–639
Mats Dahllöf & Karl Berglund, “Faces, Fights, and Families: Topic Modeling and Gendered Themes in Two Corpora of Swedish Prose Fiction”, Proceedings of the Digital Humanities in the Nordic Countries 4th Conference (DHN2019), 2019,
URL: http://urn.kb.se/resolve?urn=urn:nbn:se:uu:diva-382230
Andrew Goldstone, “The Doxa of Reading”, PMLA, 2017:3, pp. 636–642
Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History, Urbana: University of Illinois Press, 2013
Litteraturens historia i Sverige, 6 uppl., Berndt Olsson & Ingemar Algulin m.fl.(red.), Lund: Studentlitteratur, 2013
Litteraturhandboken, 6 uppl., Björn Linnell (red.), Stockholm: Forum, 1999
Franco Moretti, ”Conjectures on World Literature”, New Left Review, 2000:1, s. 54–68
Franco Moretti, Graphs, Maps, Trees: Abstract Models for Literary History, London: Verso, 2005
Anna Nordlund, Selma Lagerlöf. Sveriges modernaste kvinna, Stockholm: Max Ström, 2018
Ted Underwood, “A Genealogy of Distant Reading”, Digital Humanities Quarterly, 2017:2, s. 1–44, URL: http://www.digitalhumanities.org/dhq/vol/11/2/000317/000317.html
Östman, Carin, “Selma Lagerlöf – sagotant eller språkförnyare?”, Meijerbergs arkiv för svensk ordforskning, vol. 36, 2010, s. 273–277.
Samt digitaliserade verk av Selma Lagerlöf och August Strindberg, hämtade från Litteraturbanken.se.